Understanding Imbalanced Datasets and their Impact on Machine Learning
Imbalanced data is like a needle in a haystack, and imbalanced learning is the process of finding that needle accurately and efficiently.


Imbalanced learning is a subset of machine learning that deals with datasets in which the distribution of classes is significantly imbalanced. In such datasets, the number of instances of one class is much higher than the other class or classes. For example, in a binary classification problem, if there are 1000 instances of class A and only 10 instances of class B, the dataset is considered imbalanced.
Imbalanced datasets are common in many real-world scenarios, such as fraud detection, medical diagnosis, and anomaly detection. Identifying the instances of the rare class is vital in such scenarios, and the focus is on identifying instances of the rare class accurately.
A challenging aspect of balanced learning is that traditional machine learning algorithms tend to perform poorly on such datasets. For example, if we use accuracy as the evaluation metric, a classifier that always predicts the majority of classes will have high accuracy. However, it is not a useful model.
To address the challenges of imbalanced learning, several techniques have been proposed. These techniques can be broadly classified into two categories: data-level techniques and algorithm-level techniques.
Data-level techniques involve manipulating the dataset to balance class distribution. Some data-level techniques are:
Random Undersampling: In this technique, the instances of the majority class are randomly removed from the dataset until a balance is achieved between the classes.
Random Oversampling: In this technique, instances of the minority class are randomly duplicated to balance the class distribution.
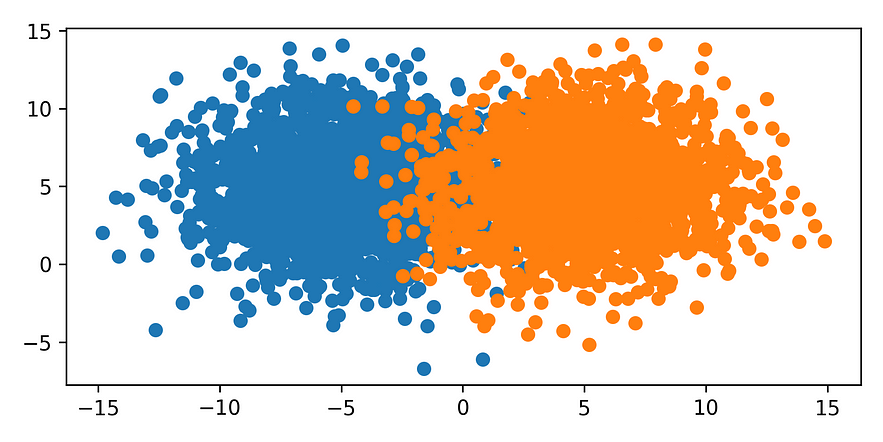
Synthetic Minority Over-sampling Technique (SMOTE): In this technique, distinct instances of the minority class are generated by interpolating existing instances and Tomek Link is one of the part where minority class elements were generated and majority class elements were reduced from the border to create clear distinction between classes.
Algorithm-level techniques involve modifying the algorithm to handle imbalanced data. Some algorithm-level techniques are:
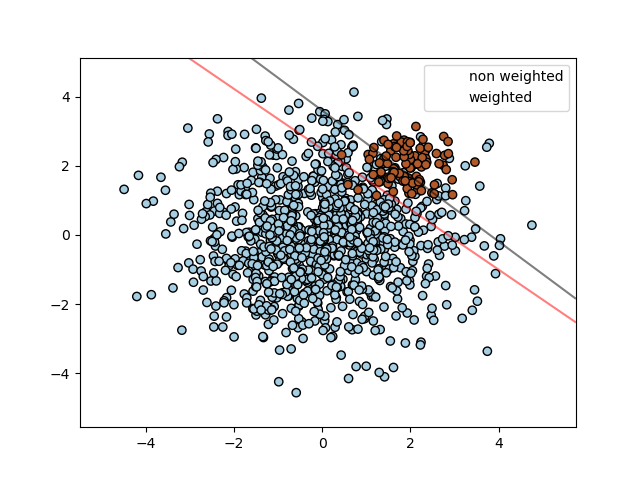
Cost-sensitive learning: In this technique, the cost of misclassifying instances of the minority class is increased, which encourages the algorithm to focus on correctly classifying the minority class.
Ensemble methods: In this technique, multiple models are trained on different subsets of the data, and their predictions are combined to make the final prediction. Ensemble methods can be used to create a balanced dataset by training each model on a balanced subset of the data.
One-Class Classification: In this technique, only the minority class is considered during training, and the goal is to identify instances that do not belong to the minority class.
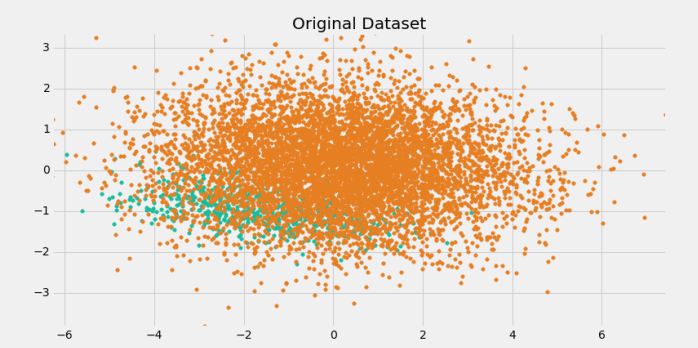
In conclusion, imbalanced learning is an important area of machine learning that deals with datasets whose class distribution is significantly imbalanced. The imbalanced nature of the data presents unique challenges that require specialized techniques to handle. Data-level and algorithm-level techniques can be used to address these challenges and improve machine learning algorithms’ performance on imbalanced datasets.